Contexte¶
Le chargement de données en base de données est essentiel pour l’analyse et la manipulation des données. Ce processus consiste à importer des données dans une base de données existante ou à créer une nouvelle base à partir de données externes.
Face à des volumes de données souvent très importants, il est crucial d’adopter une approche efficace. Cela inclut le choix du format de fichier approprié, la définition de la structure de la base de données et la gestion des erreurs lors du chargement.
Le format de fichier joue un rôle déterminant dans la manière dont les données sont stockées. Les formats couramment utilisés pour le chargement de données incluent CSV, Excel, JSON et SQL. Récemment, un nouveau format a fait son apparition : le format Parquet.
Notre objectif est de comparer ces formats de fichier afin de déterminer lequel est le plus adapté pour le chargement de données en base de données en tenant compte principalement de la taille des fichiers d’entrée.
Principe¶
Prérequis¶
Base de données PostgreSQL 16
Python 3.9 ou ultérieur
psycopg2 pour la connexion à la base de données PostgreSQL
pandas pour le traitement des données
openpyxl pour la lecture et l’écriture de fichiers Excel
Les traitements seront effectués sur un MacBook Pro M1 avec 16 Go de RAM, où la base de données et Python sont installés localement.
Mode opératoire¶
Préparation des données¶
Rien de tel que la base de données des entreprises françaises pour réaliser ce type de tests. Elle contient environ 90M de lignes et mis à jour régulièrement par l’INSEE.
Chargement des données¶
curl -XGET -L https://www.data.gouv.fr/fr/datasets/r/88fbb6b4-0320-443e-b739-b4376a012c32 -o StockEtablissementHistorique_utf8.zip
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 341 100 341 0 0 618 0 --:--:-- --:--:-- --:--:-- 618
100 1079M 100 1079M 0 0 2110k 0 0:08:43 0:08:43 --:--:-- 1959k
time unzip StockEtablissementHistorique_utf8.zip
Archive: StockEtablissementHistorique_utf8.zip
inflating: StockEtablissementHistorique_utf8.csv
unzip StockEtablissementHistorique_utf8.zip 35,24s user 1,98s system 89% cpu 41,443 total
wc -l StockEtablissementHistorique_utf8.csv
88542962 StockEtablissementHistorique_utf8.csvPréparation des données¶
Préparation des données¶
Le fichier est découpé en lots de 50_000 lignes chacun. Ces lots sont ensuite exportés dans divers formats, notamment CSV, SQL, Excel, JSON et Parquet. Il est important de noter le temps nécessaire pour cette préparation, car bien qu’il soit souvent négligé, il peut être significatif. Cela invite également à réfléchir à l’analyse du cycle de vie (ACV) des données.
python3 prepa_files.py
2025-01-08 11:38:26,179 - INFO - Chargement du fichier...
2025-01-08 11:42:37,331 - INFO - Fichier chargé...
...
Comme supposé, les délais de génération/stockage des données varie avec le type de fichier.
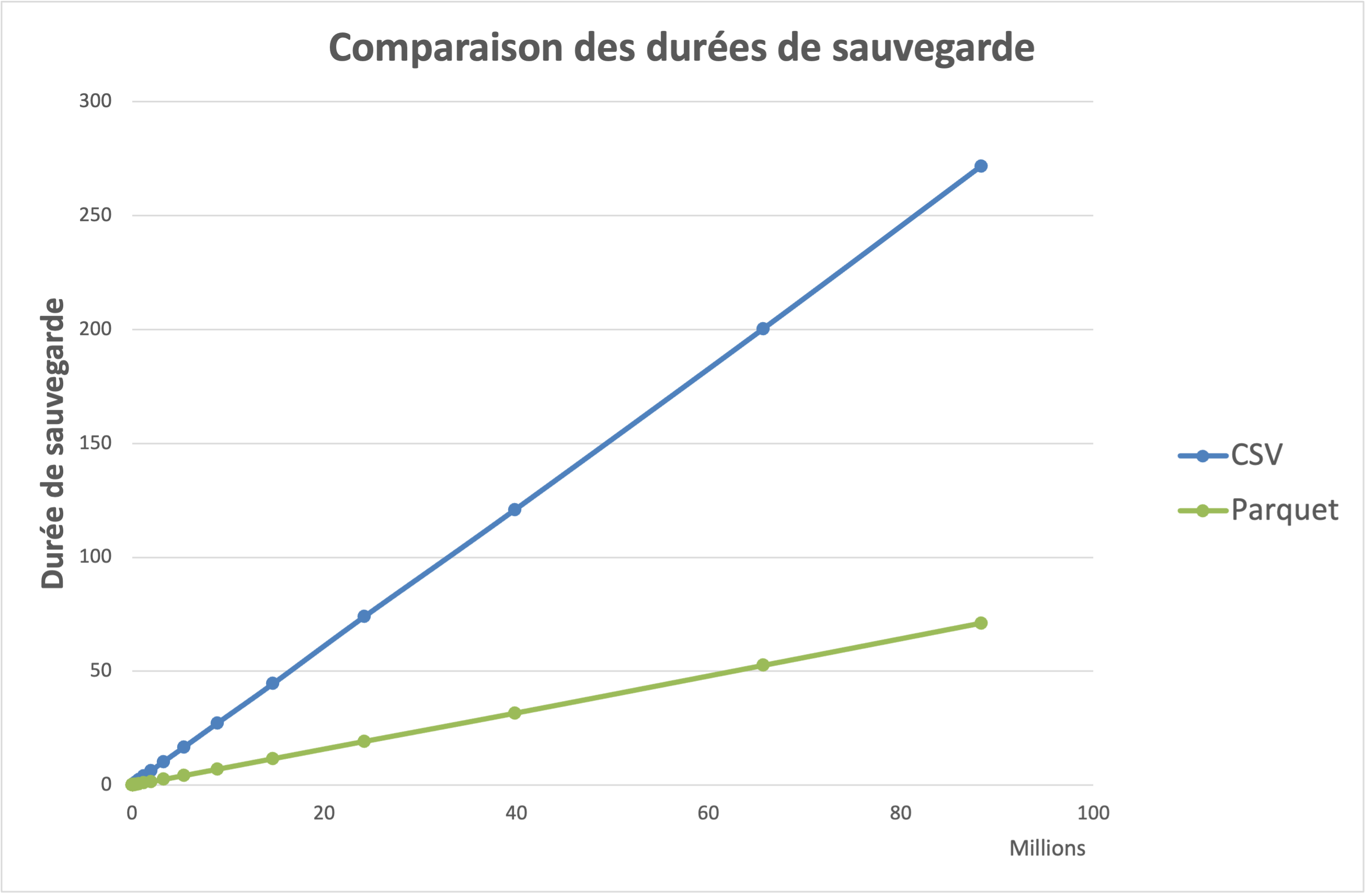
Importation des données¶
Résultats¶
En Conclusion¶
Compléments¶
Préparation des données¶
#!/usr/bin/env python3
import pandas as pd
import psutil
import math
import logging
import os
import matplotlib.pyplot as plt
logging.basicConfig(
level=logging.DEBUG, format="%(asctime)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
os.listdir(os.path.abspath(''))
# Charger le fichier CSV en une DataFrame
logger.info("Chargement du fichier...")
DATADIR = os.path.join('/','Volumes','T7','data')
fn = os.path.join(DATADIR, 'StockEtablissementHistorique_utf8.csv')
df = pd.read_csv(fn, sep=',',dtype=str)
logger.info("Fichier chargé...")
# Détermination du nombre de fichiers à générer
nb_lignes = 88_324_443 #len(df.index)
temps_csv= []
temps_pqt= []
axe_x = []
process = psutil.Process()
for i in range(1,int(math.log(nb_lignes)+1)*2):
nb_ln = min(nb_lignes, int(math.exp(i/2)))
axe_x.append(nb_ln)
start_time = process.cpu_times().user
fn_csv = f"stock_{nb_ln:011_d}.csv"
df[:nb_ln].to_csv(os.path.join(DATADIR,fn_csv), index=False)
end_time = process.cpu_times().user
temps_csv.append(end_time - start_time)
start_time = process.cpu_times().user
fn_pqt = f"stock_{nb_ln:011_d}.parquet"
df[:nb_ln].to_parquet(os.path.join(DATADIR,fn_pqt), index=False, compression=None, engine='pyarrow')
end_time = process.cpu_times().user
temps_pqt.append(end_time - start_time)
logger.info(f"Fichiers {nb_ln:011_d} créés...")
# Sauvegarde des données
df_sav = pd.DataFrame( columns=axe_x)
df_sav.loc[len(df_sav)] = temps_csv
df_sav.loc[len(df_sav)] = temps_pqt
df_sav.to_excel(os.path.join(DATADIR,'data.xlsx'), index=False)
# Création des graphes
plt.plot(axe_x, temps_csv, marker='o', label='CSV')
plt.plot(axe_x, temps_pqt, marker='o', label='Parquet')
plt.xscale('log')
plt.yscale('log')
plt.xlabel('Nombre de lignes')
plt.ylabel('Temps (secondes)')
plt.title('Temps d\'écriture du fichier CSV en fonction du nombre de lignes')
plt.grid(True)
plt.legend()
plt.show()